Between September 2021 and March 2022, we’re partnering with The Alan Turing Institute to host a series of free research seminars about how to teach AI and data science to young people.
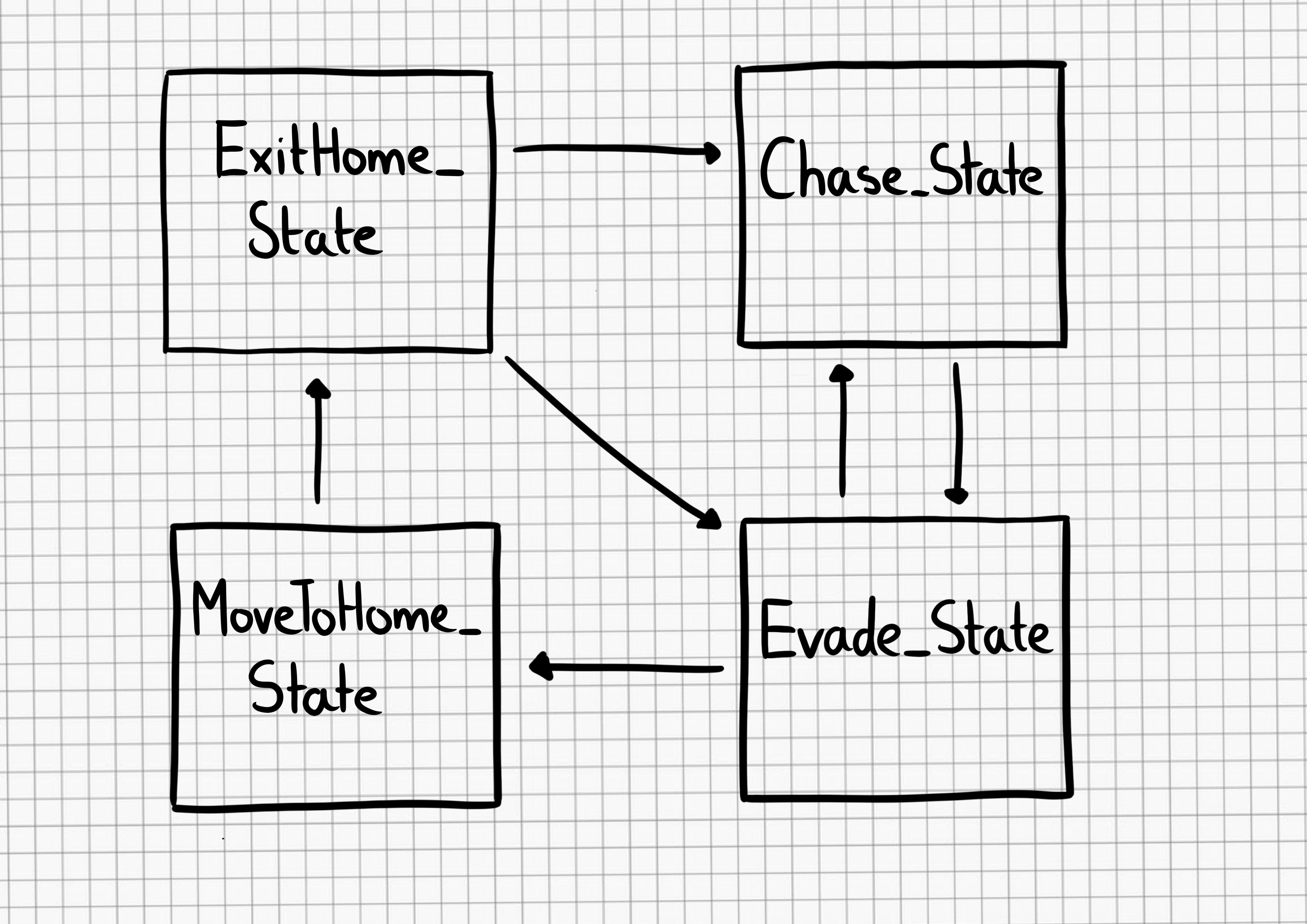
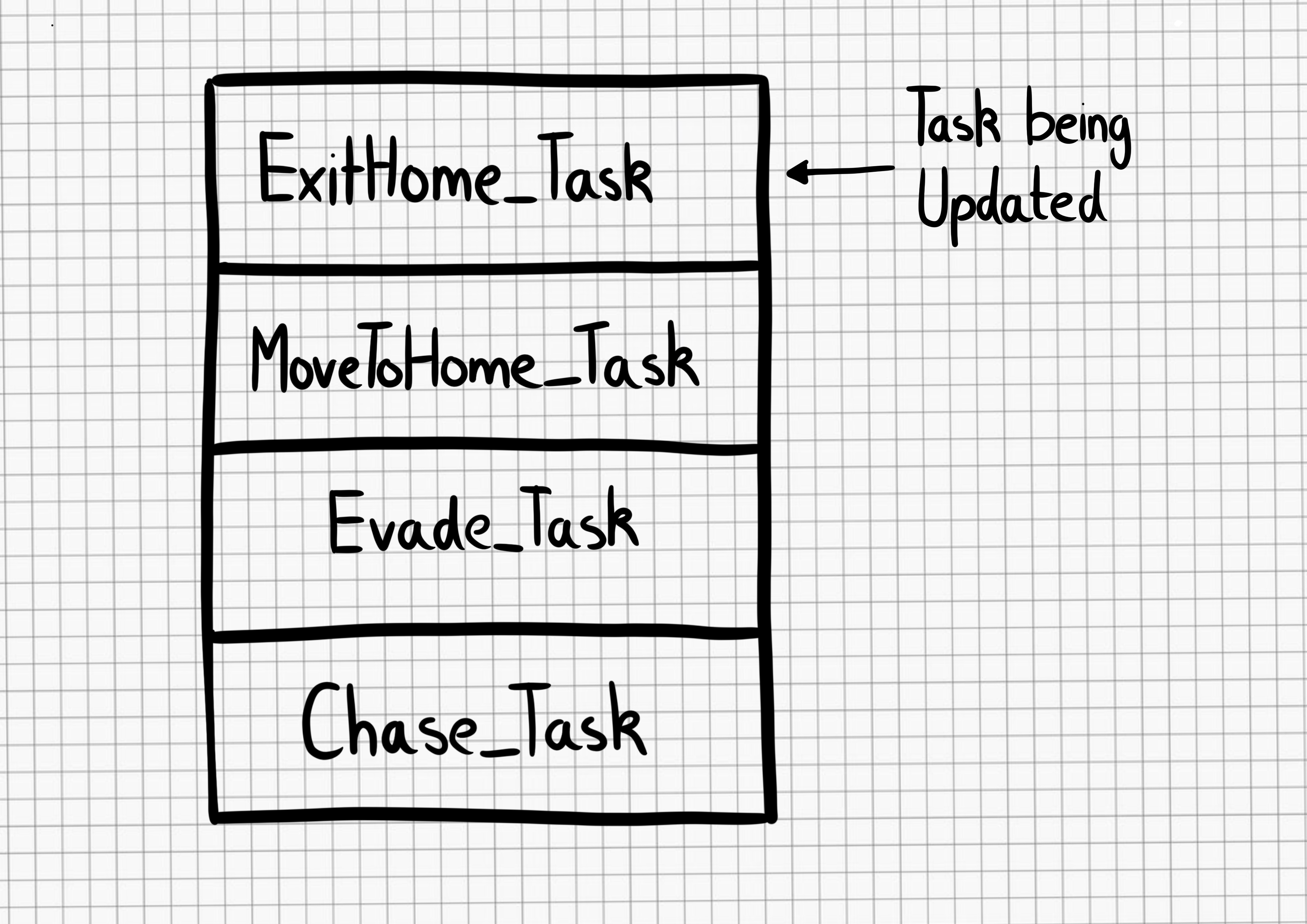
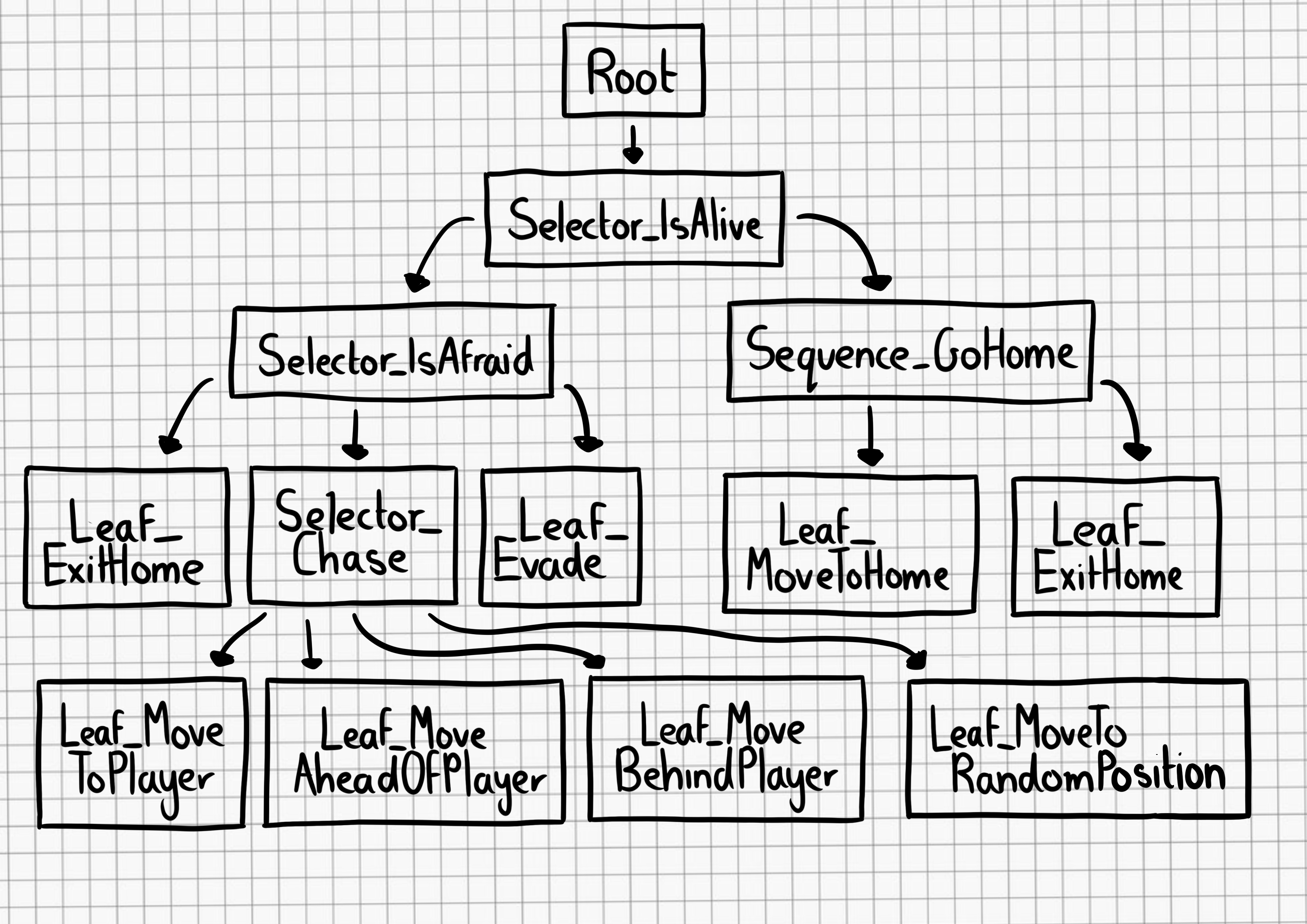
In the second seminar of the series, we were excited to hear from Professor Carsten Schulte, Yannik Fleischer, and Lukas Höper from the University of Paderborn, Germany, who presented on the topic of teaching AI and machine learning (ML) from a data-centric perspective. Their talk raised the question of whether and how AI and ML should be taught differently from other themes in the computer science curriculum at school.
Machine behaviour — a new field of study?
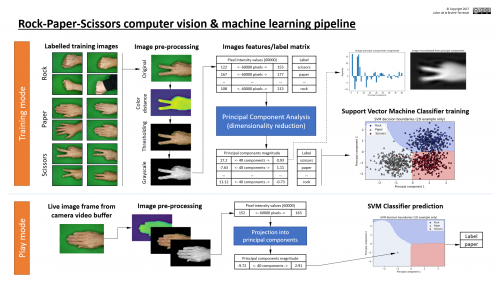
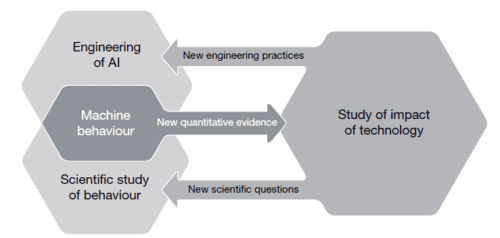
The rationale behind the speakers’ work is a concept they call hybrid interaction system, referring to the way that humans and machines interact. To explain this concept, Carsten referred to a 2019 article published in Nature by Iyad Rahwan and colleagues: Machine hehaviour. The article’s authors propose that the study of AI agents (complex and simple algorithms that make decisions) should be a separate, cross-disciplinary field of study, because of the ubiquity and complexity of AI systems, and because these systems can have both beneficial and detrimental impacts on humanity, which can be difficult to evaluate. (Our previous seminar by Mhairi Aitken highlighted some of these impacts.) The authors state that to study this field, we need to draw on scientific practices from across different fields, as shown below:
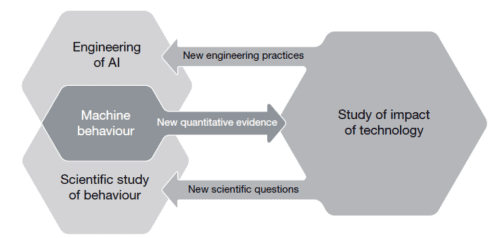
In establishing their argument, the authors compare the study of animal behaviour and machine behaviour, citing that both fields consider aspects such as mechanism, development, evolution and function. They describe how part of this proposed machine behaviour field may focus on studying individual machines’ behaviour, while collective machines and what they call ‘hybrid human-machine behaviour’ can also be studied. By focusing on the complexities of the interactions between machines and humans, we can think both about machines shaping human behaviour and humans shaping machine behaviour, and a sort of ‘co-behaviour’ as they work together. Thus, the authors conclude that machine behaviour is an interdisciplinary area that we should study in a different way to computer science.
Carsten and his team said that, as educators, we will need to draw on the parameters and frameworks of this machine behaviour field to be able to effectively teach AI and machine learning in school. They argue that our approach should be centred on data, rather than on code. I believe this is a challenge to those of us developing tools and resources to support young people, and that we should be open to these ideas as we forge ahead in our work in this area.
Ideas or artefacts?
In the interpretation of computational thinking popularised in 2006 by Jeanette Wing, she introduces computational thinking as being about ‘ideas, not artefacts’. When we, the computing education community, started to think about computational thinking, we moved from focusing on specific technology — and how to understand and use it — to the ideas or principles underlying the domain. The challenge now is: have we gone too far in that direction?
Carsten argued that, if we are to understand machine behaviour, and in particular, human-machine co-behaviour, which he refers to as the hybrid interaction system, then we need to be studying artefacts as well as ideas.
Throughout the seminar, the speakers reminded us to keep in mind artefacts, issues of bias, the role of data, and potential implications for the way we teach.
Studying machine learning: a different focus
In addition, Carsten highlighted a number of differences between learning ML and learning other areas of computer science, including traditional programming:
- The process of problem-solving is different. Traditionally, we might try to understand the problem, derive a solution in terms of an algorithm, then understand the solution. In ML, the data shapes the model, and we do not need a deep understanding of either the problem or the solution.
- Our tolerance of inaccuracy is different. Traditionally, we teach young people to design programs that lead to an accurate solution. However, the nature of ML means that there will be an error rate, which we strive to minimise.
- The role of code is different. Rather than the code doing the work as in traditional programming, the code is only a small part of a real-world ML system.
These differences imply that our teaching should adapt too.

ProDaBi: a programme for teaching AI, data science, and ML in secondary school
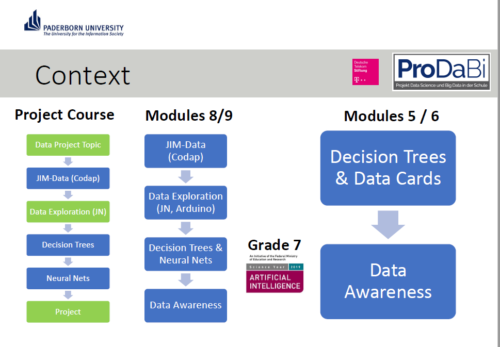
In Germany, education is devolved to state governments. Although computer science (known as informatics) was only last year introduced as a mandatory subject in lower secondary schools in North Rhine-Westphalia, where Paderborn is located, it has been taught at the upper secondary levels for many years. ProDaBi is a project that researchers have been running at Paderborn University since 2017, with the aim of developing a secondary school curriculum around data science, AI, and ML.
The ProDaBi curriculum includes:
- Two modules for 11- to 12-year-olds covering decision trees and data awareness (ethical aspects), introduced this year
- A short course for 13-year-olds covering aspects of artificial intelligence, through the game Hexapawn
- A set of modules for 14- to 15-year-olds, covering data science, data exploration, decision trees, neural networks, and data awareness (ethical aspects), using Jupyter notebooks
- A project-based course for 18-year-olds, including the above topics at a more advanced level, using Codap and Jupyter notebooks to develop practical skills through projects; this course has been running the longest and is currently in its fourth iteration
Although the ProDaBi project site is in German, an English translation is available.
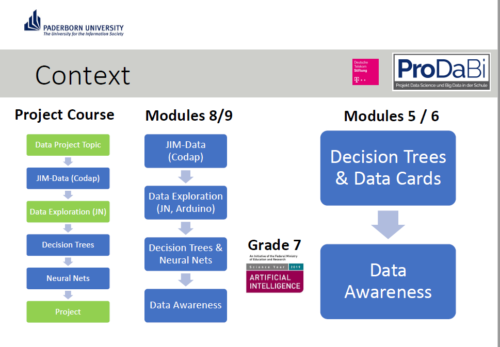
Our speakers described example activities from three of the modules:
- Hexapawn, a two-player game inspired by the work of Donald Michie in 1961. The purpose of this activity is to support learners in reflecting on the way the machine learns. Children can then relate the activity to the behavior of AI agents such as autonomous cars. An English version of the activity is available.
- Data cards, a series of activities to teach about decision trees. The cards are designed in a ‘Top Trumps’ style, and based on food items, with unplugged and digital elements.
- Data awareness, a module focusing on the amount of data an individual can generate as they move through a city, in this case through the mobile phone network. Children are encouraged to reflect on personal data in the context of the interaction between the human and data-driven artefact, and how their view of the world influences their interpretation of the data that they are given.
Questioning how we should teach AI and ML at school
There was a lot to digest in this seminar: challenging ideas and some new concepts, for me anyway. An important takeaway for me was how much we do not yet know about the concepts and skills we should be teaching in school around AI and ML, and about the approaches that we should be using to teach them effectively. Research such as that being carried out in Paderborn, demonstrating a data-centric approach, can really augment our understanding, and I’m looking forward to following the work of Carsten and his team.
Carsten and colleagues ended with this summary and discussion point for the audience:
“‘AI education’ requires developing an adequate picture of the hybrid interaction system — a kind of data-driven, emergent ecosystem which needs to be made explicitly to understand the transformative role as well as the technological basics of these artificial intelligence tools and how they are related to data science.”
You can catch up on the seminar, including the Q&A with Carsten and his colleagues, here:
[youtube https://www.youtube.com/watch?v=MlK7SgOTiCo?feature=oembed&w=500&h=281]
Join our next seminar
This seminar really extended our thinking about AI education, and we look forward to introducing new perspectives from different researchers each month. At our next seminar on Tuesday 2 November at 17:00–18:30 BST / 12:00–13:30 EDT / 9:00–10:30 PDT / 18:00–19:30 CEST, we will welcome Professor Matti Tedre and Henriikka Vartiainen (University of Eastern Finland). The two Finnish researchers will talk about emerging trajectories in ML education for K-12. We look forward to meeting you there.
Carsten and their colleagues are also running a series of seminars on AI and data science: you can find out about these on their registration page.
You can increase your own understanding of machine learning by joining our latest free online course!
[1] Rahwan, I., Cebrian, M., Obradovich, N., Bongard, J., Bonnefon, J. F., Breazeal, C., … & Wellman, M. (2019). Machine behaviour. Nature, 568(7753), 477-486.
Website: LINK










 Website:
Website: